字符编码之五:简体汉字编码方案(GB2312、GBK、GB18030、GB13000)以及全角、半角、CJK
作者:Jacky Lin 原文:刨根究底字符编码之五——简体汉字编码方案(GB2312、GBK、GB18030、GB13000)以及全角、半角、CJK
一、概述
1.
英文字母再加一些其他标点字符之类的也不会超过256个,用一个字节来表示一个字符就足够了(2^8 = 256)。但其他一些文字不止这么多字符,比如中文中的汉字就多达10多万个,一个字节只能表示 256 个字符,肯定是不够的,因此只能使用多个字节来表示一个字符。
于是当计算机被引入到中国后,相关部门设计了 GB 系列编码(“GB”为“国标”的汉语拼音首字母缩写,即“国家标准”之意)。
按照 GB 系列编码,在一段文本中,如果一个字节是0~127,那么这个字节的含义同ASCII编码,否则,这个字节和下一个字节共同组成汉字(或是GB编码定义的其他字符)。
因此,GB 系列编码向下兼容 ASCII,也就是说,如果一段用 GB 编码文本里的所有字符都在 ASCII 中有定义(即该文本全部由 ASCII 字符组成),那么这段编码和 ASCII 编码完全一样。
2.
GB编码早期收录的汉字不足一万个,基本能满足日常使用需求,但不包含一些生僻字,因此后来又进行了扩展。
最早的 GB 编码是 GB2312,后来有了在 GB2312 基础上扩展的 GBK,最新的是 GB18030,加入了一些国内少数民族的文字,一些生僻字被编到了4个字节,每扩展一次都完全保留之前版本的编码,所以每个新版本都向下兼容。
这里要指出的是,虽然都用多个字节表示一个字符,但是 GB 类的汉字编码与后文的 Unicode 编码方案 UTF-8、UTF-16、UTF-32 是毫无关系的(其中 UTF-8 对于 ASCII 字符仍用一个字节编码,而非 ASCII 字符则为多字节编码)。
3.
不过,也正因为不得不使用多个字节来表示一个字符,相较于只使用单个字节的 ASCII 编码方案,GB 类编码方案与后面要介绍的Unicode 编码方案一样,无疑导致了更高的复杂度。
比如,当多字节字符与原先的ASCII字符混用时:
要么将原先的ASCII字符重新编码为多个字节表示,以便与其他多字节字符统一起来(UTF-16、UTF-32等采用的是这种方法);
要么保持ASCII字符为单个字节编码不变,但将其他多字节字符编码中的各个字节的最高位(首位)设为1,以避免与字节最高位为0的ASCII编码相冲突(GB、UTF-8等采用的是这种方法)。
前者具有更高的空间复杂度,因为原先只需要单个字节表示的ASCII字符,现在也必须用多个字节来表示,显然更为耗费存储空间;后者则具有更高的时间复杂度,因为为了避免冲突以及其他种种考虑(比如扩展性、容错性等),使用了更为复杂的编码算法(encodingalgorithm),无疑更为耗费计算时间。
而且,无论是前者还是后者,若多字节编码中采用的又是多字节码元(Code Unit)的话(如UTF-16、UTF-32编码采用的就是多字节码元,而UTF-8中的非ASCII字符虽然也是多字节编码,但采用的却是单字节码元),由于历史的原因,又进一步引发了更为麻烦的字节序(Byte-Order)问题。(编码算法、码元、字节序的相关介绍,详见后文解释)
二、GB2312
1.
GB2312 编码方案,即《信息交换用汉字编码字符集——基本集》,是由中国国家标准总局于1980年发布、1981年5月1日开始实施的一套国家标准,标准号为GB2312-1980。
GB2312 编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持 GB2312。
2.
GB2312 编码为了避免与 ASCII 字符编码(0~127)相冲突,规定表示一个汉字的编码(即汉字内码)的字节其值必须大于127(即字节的最高位为1),并且必须是两个大于127的字节连在一起来共同表示一个汉字(GB2312为双字节编码),前一字节称为高字节,后一字节称为低字节;而一个字节的值若小于127(即字节的最高位为0),自然是仍表示一个原来的ASCII字符(ASCII为单字节编码)。
因此,可以认为 GB2312 是对 ASCII 的中文扩展 (即GB2312与ASCII相兼容),正如 EASCII 是对 ASCII 的欧洲文字扩展一样。
不过,很显然的是,GB2312 与 EASCII 码的 128~255 这段扩展部分所表示的字符是不同的。也就是说,GB2312 与 EASCII 虽然都兼容 ASCII,但 GB2312 并不兼容 EASCII 的扩展部分。
事实上,目前世界上除 ASCII 之外的其它通行的字符编码方案,基本上都兼容 ASCII,但相互之间并不兼容。
(笨笨阿林原创文章,转载请注明出处)
3.
GB 2312 标准共收录 6763 个汉字,其中一级汉字 3755 个,二级汉字 3008 个;同时,除了汉字,GB2312还收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
可能是出于显示上视觉美观的考虑,除汉字之外的682个字符中,甚至包括了 ASCII 里本来就有的数字、标点、字母等字符。也就是说,这些ASCII里原来就有的单字节编码的字符,又再编了两个字节长的 GB2312 编码版本。这682个字符就是常说的“全角”字符,而这682个字符中所对应的 ASCII 字符就被称之为“半角”字符。
【附:全角、半角】
全角字符是中文显示及双字节中文编码的历史遗留问题。
早期的点阵显示器上由于像素有限,原先 ASCII 西文字符的显示宽度(比如8像素的宽度)用来显示汉字有些捉襟见肘(实际上早期的针式打印机在打印输出时也存在这个问题),因此就采用了两倍于 ASCII 字符的显示宽度(比如 16 像素的宽度)来显示汉字。
这样一来,ASCII 西文字符在显示时其宽度为汉字的一半。或许是为了在西文字符与汉字混合排版时,让西文字符能与汉字对齐等视觉美观上的考虑,于是就设计了让西文字母、数字和标点等特殊字符在外观视觉上也占用一个汉字的视觉空间(主要是宽度),并且在内部存储上也同汉字一样使用2个字节进行存储的方案。这些与汉字在显示宽度上一样的字符就被称之为全角字符。
后来,其中的一些全角字符因为比较有用,就得到了广泛应用(比如全角的逗号“,”、问号“?”、感叹号“!”、空格“ ”等,这些字符在输入法中文输入状态下的半角与全角是一样的,英文输入状态下全角跟中文输入状态一样,但半角大约为全角的二分之一宽),专用于中日韩文本,成为了标准的中日韩标点字符。而其它的许多全角字符则逐渐失去了价值(现在很少需要让纯文本的中文和西文字字对齐了),就很少再用了。
现在全球字符编码的事实标准是 Unicode 字符集及基于此的 UTF-8、UTF-16 等编码实现方式。Unicode 吸纳了许多遗留(legacy)编码,并且为了兼容性而保留了所有字符。因此中文编码方案中的这些全角字符也保留下来了,而国家标准也仍要求字体和软件都支持这些全角字符。
不过,半角和全角字符的关系在 UTF-8、UTF-16 等中不再是简单的1字节和2字节的关系了。具体参见后文。
——综合了知乎《中文输入法为什么会有全角和半角的区别?》下多位答主的回答,有多处修改

三、GB13000
1.
为了便于多个文种的同时处理,国际标准化组织下属编码字符集工作组制定了新的编码字符集标准——ISO/IEC 10646(与统一联盟制定的 Unicode 标准兼容,两者的关系详见后文)。
该标准第一次颁布是在1993年,当时只颁布了其第一部分,即ISO/IEC 10646.1:1993,收录中国大陆、台湾、日本及韩国通用字符集的汉字,总共20,902个。制定这个标准的目的是对世界上的所有字符统一编码,以实现世界上所有字符在计算机上的统一处理。
2.
中国相应的国家标准是GB13000.1-1993《信息技术通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面》。
2010年又发布了替代标准——GB13000-2010《信息技术通用多八位编码字符集(UCS)》,此标准等同于国际标准ISO/IEC 10646:2003《信息技术通用多八位编码字符集(UCS)》。
GB13000 与国际标准 ISO/IEC10646 及 Unicode 标准目前在基本平面(即BMP,详见后文)上保持一致。
四、GBK
1.
GB2312-1980 共收录6763个汉字,覆盖了中国大陆99.75%的使用频率,基本满足了汉字的计算机处理需要。但对于人名、古汉语等方面出现的罕用字、生僻字,GB2312不能处理,如部分在GB2312-1980推出以后才简化的汉字(如“啰”)、部分人名用字(如前总理朱镕基的“镕”字)、台湾及香港使用的繁体字、日语及朝鲜语汉字等,并未收录在内。
于是利用 GB2312-1980 未使用的码点空间,收录 GB13000.1-1993 的全部字符,于1995年又发布了《汉字内码扩展规范(GBK)》(Guo-Biao Kuozhan国家标准扩展码,是根据GB13000.1-1993,对GB2312-1980的扩展;英文全称Chinese Internal Code Specification)。
2.
不过,虽然GBK收录了GB13000.1-1993的全部字符,但编码方式并不相同。
GBK 跟 GB2312 一样是双字节编码,然而,GBK只要求第一个字节即高字节是大于 127 就固定表示这是一个汉字的开始(0~127当然表示的还是ASCII字符),不再要求第二个字节即低字节也必须是127号之后的编码。这样,作为同样是双字节编码的GBK才可以收录比GB2312更多字符。
GBK 字符集向后完全兼容 GB2312,还支持 GB2312-1980 不支持的部分中文简体、中文繁体、日文假名,还包括希腊字母以及俄语字母等字母(不过这个编码不支持韩国文字,也是其在实际使用中与Unicode编码相比欠缺的部分),共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一体。
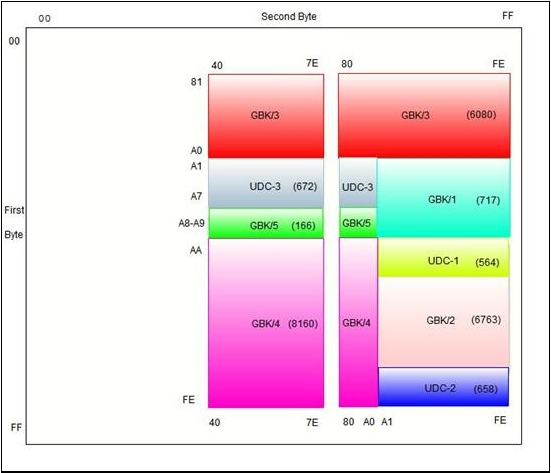
GBK 的编码框架(Code Scheme):
其中GBK1 收录除GB2312 符号外的增补符号,
GBK2 收录GB2312 汉字,GBK3 收录CJK 汉字,
GBK4 收录CJK 汉字和增补汉字,
GBK5 为非中文字符集,UDC为用户自定义字符区
微软早在Windows 95简体中文版中就采用了GBK编码,也就是对微软内部之前的CP936字码表(Code Page 936)进行了扩展(之前CP936和GB2312-1980一模一样)。
微软的CP936通常被视为等同于GBK,连IANA(Internet Assigned Numbers Authority互联网号码分配局)也以“CP936”为“GBK”之别名。
但事实上比较起来,GBK 定义之字符较 CP936 多出 95 个(15个非汉字及80个汉字),皆为当时未收入ISO 10646 / Unicode的符号。
有说是微软在GB2312的基础上扩展制订了GBK,然后GBK才成为“国家标准”(也有说GBK不是国家标准,只是“技术规范指导性文件”);但网上也有资料说是先有GBK(由全国信息技术标准化技术委员会于1995年12月1日制定),然后微软才在其内部所用的CP936代码页中以GBK为参考进行了扩展。
五、GB18030
1.
中国国家质量技术监督局于2000年3月17日推出了GB18030-2000标准,以取代GBK。GB18030-2000除保留全部GBK编码汉字之外,在第二字节再度进行扩展,增加了大约一百个汉字及四位元组编码空间。
GB18030《信息交换用汉字编码字符集基本集的补充》是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。
2.
2005年,GB18030编码方案又进行了扩充,于是又有了GB18030-2005《信息技术中文编码字符集》。如前所述,GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK中日韩统一表意文字扩充A的汉字;而GB18030-2005的主要特点是在GB18030-2000基础上又增加了CJK中日韩统一表意文字扩充B的汉字。
微软也为GB18030定义了代码页(Codepage):CP54936,但是这个代码页实际上并没有真正使用(在Windows 7的“控制面板”-“区域和语言”-“管理”-“非Unicode程序的语言”中没有提供选项;在Windows cmd命令行中可通过命令chcp 54936更改,之后在cmd可显示中文,但却不支持中文输入)。
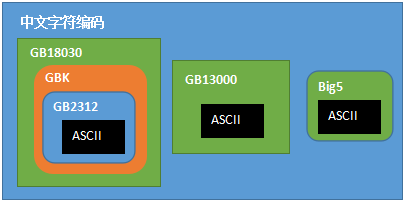
各汉字(中文字符) 编码方案之间的关系
(Big5 为繁体汉字编码方案,主要通行于台港地区,本文不作详细介绍)
六、CJK中日韩统一表意文字
1.
CJK指的是中日韩统一表意文字(CJK Unified Ideographs),也称统一汉字(Unihan),目的是要把分别来自中文(包含壮文)、日文、韩文、越文中,起源相同、本义相同、形状一样或稍异的表意文字在 Unicode 标准及 ISO/IEC 10646 标准内赋予相同的码点值。(Unicode标准及ISO/IEC 10646标准后文有详细解释)
CJK是中文(Chinese)、日文(Japanese)、韩文(Korean)三国文字英文首字母的缩写。顾名思义,它能够支持这三种文字,但实际上,CJK 能够支持包括中文(包含壮文)、日文、韩文、越文在内的多种亚洲双字节文字。
2.
所谓“起源相同、本义相同、形状一样或稍异的表意文字”,主要为汉字,包括繁体字、简体字;但也有仿汉字,包括方块壮字、日本汉字(漢字/かんじ)、韩国汉字(漢字/한자)、越南的喃字(𡨸喃/Chữ Nôm)与儒字(𡨸儒/Chữ Nho)等。
此计划原本只包含中文、日文及韩文中所使用的汉字和仿汉字,统称中日韩(CJK)统一表意文字(Unified Ideographs)。后来,此计划才加入了越南文的喃字,所以又合称为中日韩越(CJKV)统一表意文字。
七、小结
1.
GB 类的字符集均属于双字节字符集 DBCS(Double Byte Character Set)。
在 DBCS 系列编码方案里,最大的特点是两字节长的中文字符和一字节长的英文字符( ASCII 字符)相兼容,可以并存于同一个文件内。
2.
因此,写程序时为了支持中文处理,必须要注意字符串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。
使用GB类编码方案时一般都要时刻记住:一个汉字由两个字节组成(即一个汉字占用的空间相当于两个英文字符占用的空间)。
【预告:下一篇将重点剖析非常容易令人困惑的简体汉字编码中的 区位码、国标码(交换码)、内码(机内码)、外码(输入码)、字形码(输出码)的区别及关系,敬请关注!】